ONOS是一个分布式的控制器,为了提高数据的读写效率,采用自实现的基于In-Memory的Key-Value数据存储系统。针对实际的需要,不同的数据模型采用不同的数据一致性方法,即强一致性(strong consistency)和最终一致性(eventually consistency)。ONOS使用raft协议实现强一致性,使用anti-entropy(gossip)协议实现最终一致性。
1. ONOS系统架构演进
ONOS当前的数据采用In-Memory方式存储和同步,其架构师Madan Jampani来自Amazon,是Amazon的Dynamo的核心架构师之一,07年就在业界发表过分布式存储论文Dynamo。另一位Jordan Halterman就是Raft协议的Java实现版CopyCat,分布式协同框架Atomix的作者。然而,最初的ONOS版本使用的是一些比较成熟的第三方的数据库存储系统。如ONOS的第一个样机使用Cassandra作为数据分布式数据存储系统,使用Zookeeper实现设备与ONOS的主从关系控制器,实现ONOS集群管理。为了提高ONOS的性能,ONOS正式发布的1.0版本采用的是embedded模式下的Hazelcast作为基于内存的分布式存储系统,embedded模式下的Hazelcast采用peer-to-peer的方式通信,每一个ONOS instance作为一个peer,ONOS的业务数据存储在用一个JVM中,从而提高ONOS cluster的性能。
然而,使用第三方库的风险是不可控的,尤其在第三方库版本升级或有bug时,这对于想要实现一个搞性能,高可靠的控制器来说是不可接受的,因此,ONOS在后面的版本中使用自研的基于raft协议的分布式存储系统。Raft协议比Paxo协议简单易懂,目前已经有很多语言的实现版本,ONOS使用的是基于Java实现的CopyCat版本。但ONOS没有直接使用CopyCat,而是使用了基于raft的分布式协同框架Atomix,该框架通过提供一些简单的原语接口来隐藏分布式系统中的复杂问题,如领导选择,并发控制,数据分片和复制等。
从ONOS系统架构演进的过程中,我们可以看出实现一个高性能,搞可靠的分布式系统架构并不容易,需要根据实际的业务特性付出很多尝试很创新。然而,利用已有的技术的方法快速实现一个original prototype也是一个很好的选择。
参考:
2. ONOS数据存储的一致性模型
在分布式数据存储系统中,数据的一致性模型分为两类,即强一致性和最终一致性:
- 强一致性(strong consistency):多个进程或节点在任何时刻都能读取到相同的数据,当有节点要对数据更新时,各个节点要确认对更新的值达成一致后再更新相应的数据,ONOS使用RAFT协议实现强一致性。
- 最终一致性(eventual consistency):多个进程或节点在相同的时刻可能对相同数据有不同的访问值,但经过一定时间后数据的更新会达成一致,ONOS使用事件乐观异步复制和anti-entropy(gossip)协议实现最终一致性。下面是最终一致性的实现方法:
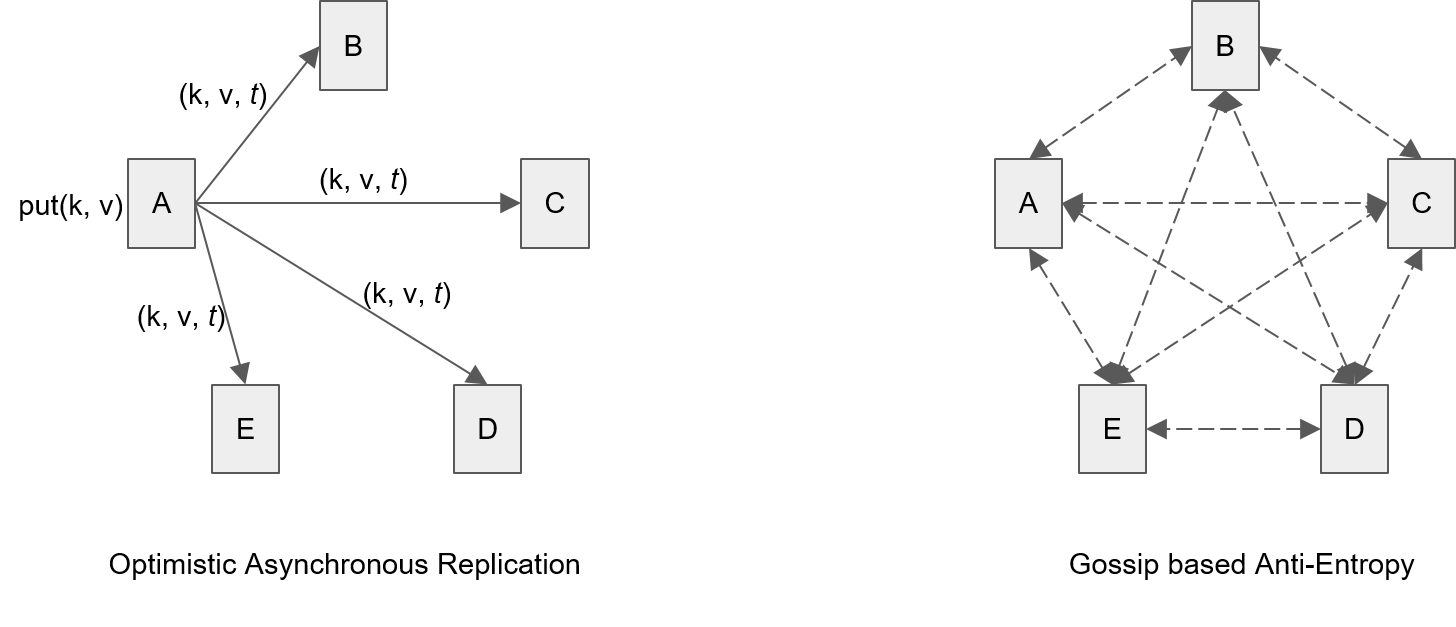
何时使用强一致性和弱一致性,这取决于系统对不同模型的一致性需求,同时要考虑实际一致性的可操作性。例如每个控制器都要有网络的全局拓扑信息,在很多情况下,拓扑信息是不变的,拓扑信息的变化是由于物理网络的变化,控制器只是拓扑信息的观察者,这在实现强一致性过程中需要很多代价,因此对于物理拓扑,ONOS使用最终一致性。事实上,传统的OSPF协议也是使用弱一致性快速收敛的。若控制器是数据变化的生产者,往往采用强一致性,如Intent下发,控制器到交换机的主从关系的维护。下面是ONOS中使用的一致性模型分类:
| 数据类型 | 一致性模型 |
|---|---|
| Network Topology, Flow Stats | 最终一致,低延迟读取 |
| Flow Rules | 乐观复制备份 |
| Application, Intents, Resource Allocations | 强一致性 |
为了隐藏数据存储的复杂性,ONOS提供了一些分布式原语(distributed primitive)来实现数据的强一致性和最终一致性存储,使用StorageService服务可以创建这些原语数据结构。如EventuallyConsistentMap<K, V>用来存储一个最终一致性map,EventuallyConsistentMap直接在本地进行数据读写操作,有节点的map值发生更新时,ONOS会广播更新时间和更新的值,其它的节点会通过比较时间戳来更新map的值。另外,当有新节点加入或有节点的数据突然丢失时,ONOS使用anti-entropy(gossip)协议来确保数据的最终一致性。而ConsistentMap<K, V>是一个实现了强一致性的map,该map最终是通过Atomix框架的raft协议实现的。但需要注意的是,强一致性也有不同的等级,如线性一致性(linearizable consistency), 可串化一致性(serializable consistency), 顺序一致性(sequential consistency)。ConsistentMap实现的一致性模型是线性一致性地写和顺序一致性地读,也就是说,一个节点执行了写操作,那么这个写操作会立即在这个节点完成,即这个写操作对当前节点后面的读操作都是可见的(linearizable consistency)。ConsistentMap并不保证这个写操作对其它节点也立即可见,但其它节点会以相同的顺序读取到当前节点的更新(sequential consistency)。
需要注意的是,实现强一致性的代价是昂贵的,为了提高数据的读取效率,可以使用本地缓存ConsistentMap的方式来提高部分读操作(如get,containsKey等操作)的读取效率,相关代码在CachingAsyncConsistentMap中实现。构建ConsistentMap时可以使用withRelaxedReadConsistency方法设置使用本地缓存的方式读取map。
参考:
Googlegroups: Using both RAFT and Anti-Entropy for consensus
Googlegroups: Why Network Topology can be used an Eventual Consistency model in ONOS
3. ONOS集群数据分片
为了提高数据的访问效率,ONOS数据采用分片式(partition or shard)存储,每一个partition有多个(默认是3个)member(ONOS node), 又称为一个raft group或partition server,每个partition的多个member使用raft协议(atomix框架的copycat实现)来保证数据的一致性,ONOS使用client-server模型来实现对不同partition数据的访问。默认的,对于n个节点的集群,有n个3-node partition,具体看查看ClusterManager源码。每个partition的数据更新是串行的(保证一致性),不同的partition的数据可以并行更新(数据分片提高数据的访问效率),使用2PC协议实现数据跨分片更新事务。下面是数据的分片复制图示:
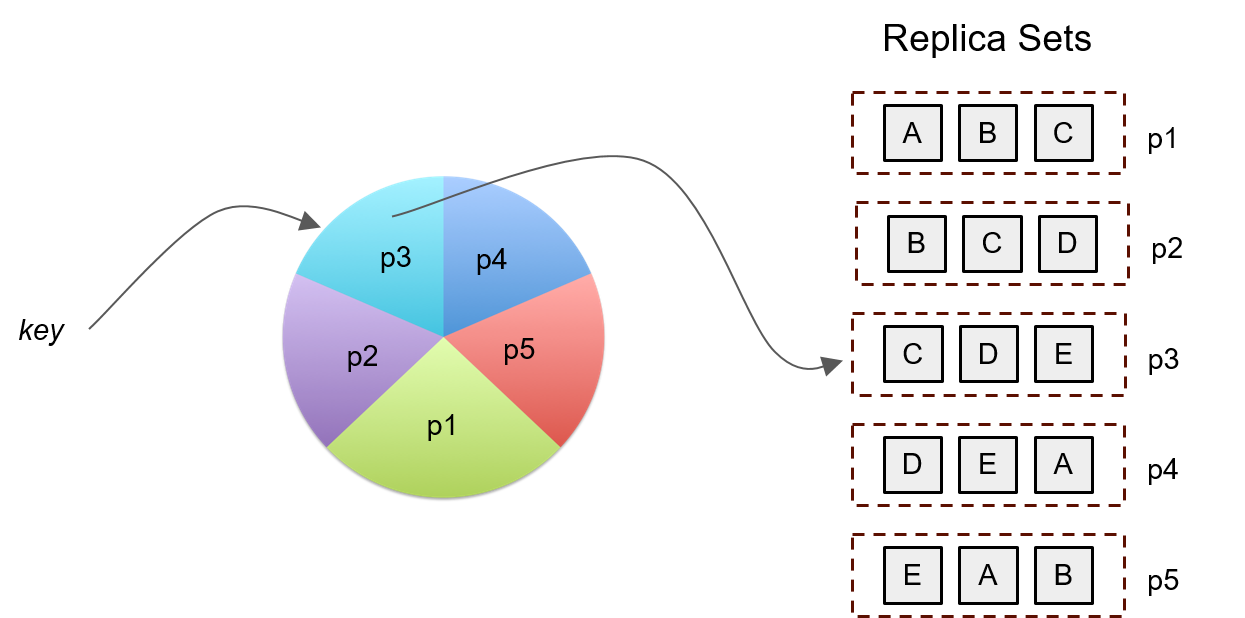
raft使用复制状态机的方式实现数据的一致性,可容忍少部分节点的故障失效,因此若数据分片大小为3,那么最多可容忍一个节点的失效。需要注意的是可容忍失效的节点数目与数据分片的个数有关,而与ONOS节点个数没有直接关系。
关于数据分片的管理和同步,可以查看PartitionService, PartitionAdminService,PartitionManager,StoragePartition,StoragePartitionClient,StoragePartitionServer等接口和类,注意:StoragePartition与StoragePartitionClient和StoragePartitionServer是相互引用的关系!下面是PartitionManager中的一段代码:
ps: 这一小段代码就用到了java8的几个重要特性,如lambda表达式,流式处理,方法引用等,很酷吧!:wink:
1 |
|
可以看出,这里根据当前当前集群中已经分配好的partition来创建对应的目录文件,从而保存相关的数据信息,数据保存在karaf运行目录下的data/partitions文件夹中,查看各个各个节点中的partition目录下的文件,发现该目录下的partitionId信息与用partitions -c查看的信息是一致的。
使用partitions命令查看当前节点存储的分片信息,使用partitions -c查看当前节点以client身份访问的所有分片信息,前者返回的是StoragePartitionServer的信息,后者返回的是StoragePartitionClient的信息,二者和Atomix的框架实现有关。事实上,一个ONOS节点保存有多个分片信息,但可能不是所有分片的信息,每个ONOS节点是所有分片的client,使用client-server访问每一个分片的数据。在onos-gen-partition中可以设置分片大小,即每个分片的member成员的个数,初始分片配置信息保存在config/cluster.json中,分片的过程在ClusterManager类中执行。
1 | onos> partitions |
其中,name表示PartitionId,term表示当前领导任期,member表示分片成员raft group),*表示当前分片成员的领导(leader)。
由于ONOS采用领导选举机制来同步信息,因而不用的ONOS实例间的信息交互可能是不对称的。
注: ONOS中还有一种work partition,用来把一些task(主要和intent相关)分配到特定的节点,每一个work partition用topic来标识,使用leadershipService选举获得work partition的leader,具体的代码在WorkPartitionManager类中实现。
4. ONOS分布式原语实现分析
ONOS提供多种的分布式原来实现分布式的操作和存储,如领导原则(LeaderElector),全局原子ID(AtomicIdGenerator),Key-Value(ConsistentMap)存储等,StorageService服务提供统一创建分布式原语的接口,使用构造器模式创建分布式原语。ONOS中每一个基于Atomix框架和Raft协议实现的分布式原语都对应的了一状态机实例,不同的状态机实例通过原语的名称进行区分,这些状态机实例共享存储在的数据分片集合中。下面以LeaderElector为例(1.11.0-SNAPSHOT),介绍分布式原语的实现和创建流程。
LeadElector的实现分析
LeadElector是针对一个特定的topic,选举一个leader,LeadElector是AsyncLeaderElector异步执行完成后的结果(即CompletableFuture.get方法返回的值),ONOS中的所有的分布式原语底层都是基于CompletableFuture异步实现的。需要注意的是,LeadElector实现的选举与raft算法里面的选举规则是不一样的,通过AsyncLeaderElector接口的注释可以发现,Atomix是通过FIFO的方式控制对一个topic标识的资源的访问来实现领导选举的。即当使用CompletableFuture<Leadership> run(String topic, NodeId nodeId)完成一次领导选举时,就会将该nodeId加入到该topic标识的队列中,所有队列中的节点都是该topic的Candidate,而队列头部的元素就是该topic的leader。ONOS中org.onosproject.store.primitives.resources.impl包下的AtomixLeaderElector类是AsyncLeaderElector底层实现,而LeaderElector对应的状态机操作在AtomixLeaderElectorService类中实现。事实上,每一个基于Atomix实现的原语都有一个AtomixXXX和AtomixXXXService的实现类。例如,AtomixLeaderElector类中的领导选举run方法的代码实现如下:1
2
3
4
5
public CompletableFuture<Leadership> run(String topic, NodeId nodeId) {
return proxy.<Run, Leadership>invoke(RUN, SERIALIZER::encode, new Run(topic, nodeId), SERIALIZER::decode)
.whenComplete((r, e) -> cache.invalidate(topic));
}该方法通过一个
RaftProxy与Raft状态机进行交互,RUN就是这次操作的类型,代表的是一次写入操作,该状态机操作是通过AtomixLeaderElectorService类中的run方法实现的,返回的是一个Leadership类型的对象。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32/**
* Applies an {@link AtomixLeaderElectorOperations.Run} commit.
* @param commit commit entry
* @return topic leader. If no previous leader existed this is the node that just entered the race.
*/
public Leadership run(Commit<? extends Run> commit) {
try {
String topic = commit.value().topic();
Leadership oldLeadership = leadership(topic);
Registration registration = new Registration(commit.value().nodeId(), commit.session().sessionId().id());
elections.compute(topic, (k, v) -> {
if (v == null) {
return new ElectionState(registration, termCounter(topic)::incrementAndGet);
} else {
if (!v.isDuplicate(registration)) {
return new ElectionState(v).addRegistration(registration, termCounter(topic)::incrementAndGet);
} else {
return v;
}
}
});
Leadership newLeadership = leadership(topic);
if (!Objects.equal(oldLeadership, newLeadership)) {
notifyLeadershipChange(oldLeadership, newLeadership);
}
return newLeadership;
} catch (Exception e) {
logger().error("State machine operation failed", e);
throw Throwables.propagate(e);
}
}LeadElector的创建流程
LeadElector是LeadershipService实现的基础,在DistributedLeadershipStore类中,一个LeadElector实例的创建方法如下:1
2
3
4leaderElector = storageService.leaderElectorBuilder() //1
.withName("onos-leadership-elections") //2
.build() //3
.asLeaderElector(); //4其中,1方法在
StorageManager类中实现,返回的是DefaultLeaderElectorBuilder类型,DefaultLeaderElectorBuilder传入的参数是实现了DistributedPrimitiveCreator接口的FederatedDistributedPrimitiveCreator类型的实例,该实例在StorageManager中初始化:1
2
3
4
5
6
7
8
9
10
public void activate() {
Map<PartitionId, DistributedPrimitiveCreator> partitionMap = Maps.newHashMap();
partitionService.getAllPartitionIds().stream()
.filter(id -> !id.equals(PartitionId.from(0)))
.forEach(id -> partitionMap.put(id, partitionService.getDistributedPrimitiveCreator(id)));
federatedPrimitiveCreator = new FederatedDistributedPrimitiveCreator(partitionMap);
transactionManager = new TransactionManager(this, partitionService);
log.info("Started");
}3方法将通过
FederatedDistributedPrimitiveCreator.newAsyncLeaderElector方法创建一个AsyncLeaderElector,FederatedDistributedPrimitiveCreator.newAsyncLeaderElector方法实现如下:1
2
3
4
5
6
7
8
9
10
11
12
public AsyncLeaderElector newAsyncLeaderElector(String name, long leaderTimeout, TimeUnit timeUnit) {
checkNotNull(name);
Map<PartitionId, AsyncLeaderElector> leaderElectors =
Maps.transformValues(members,
partition -> partition.newAsyncLeaderElector(name, leaderTimeout, timeUnit));
Hasher<String> hasher = topic -> {
int hashCode = Hashing.sha256().hashString(topic, Charsets.UTF_8).asInt();
return sortedMemberPartitionIds.get(Math.abs(hashCode) % members.size());
};
return new PartitionedAsyncLeaderElector(name, leaderElectors, hasher);
}其中
members表示的是一个Map<PartitionId, DistributedPrimitiveCreator>类型的partitionMap,通过上面的代码片段可知该信息通过partitionService获得。由于ONOS对数据进行分片存储,分布式原语会在每一个partition上都创建一个实例。因此每一个partition都有一个DistributedPrimitiveCreator接口的实现,StoragePartitionClient负责该接口的最终实现,然后各个partition根据StoragePartitionClient.newAsyncLeaderElector方法创建一个AsyncLeaderElector实例,通过下面的代码片段可知AsyncLeaderElector最终是通过AtomixLeaderElector实现的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public AsyncLeaderElector newAsyncLeaderElector(String name) {
AtomixLeaderElector leaderElector = new AtomixLeaderElector(client.newProxyBuilder()
.withName(name)
.withServiceType(DistributedPrimitive.Type.LEADER_ELECTOR.name())
.withReadConsistency(ReadConsistency.LINEARIZABLE)
.withCommunicationStrategy(CommunicationStrategy.LEADER)
.withTimeout(Duration.ofSeconds(5)) //5
.withMaxRetries(5)
.build()
.open()
.join());
leaderElector.setupCache().join();
return leaderElector;
}注意上面代码中的5方法设置该原语实例(client)与状态机会话(
RaftSession)的timeout,即当一个client超过timeout指定的时间(5s)未与状态机有heartbeat交互时,该会话就会结束,并触发AtomixLeaderElectorService中的onExpire和onClose方法。上述代码返回一个AtomixLeaderElector实例,最后不同分片的AtomixLeaderElector实例封装在一个实现了AsyncLeaderElector接口的PartitionedAsyncLeaderElector对象中,以run方法为例,可知PartitionedAsyncLeaderElector会更据topic和hash函数,找到对应的partion中的AtomixLeaderElector实例,并执行AtomixLeaderElector.run方法:1
2
3
4
5
6
7
8
9
10
11
12
public CompletableFuture<Leadership> run(String topic, NodeId nodeId) {
return getLeaderElector(topic).run(topic, nodeId);
}
/**
* Returns the leaderElector (partition) to which the specified topic maps.
* @param topic topic name
* @return AsyncLeaderElector to which topic maps
*/
private AsyncLeaderElector getLeaderElector(String topic) {
return partitions.get(topicHasher.hash(topic));
}另外,2方法设置该原语实例的名称,不同的原语实例需要使用不同的名称进行标记;4方法返回一个异步计算完成后的
LeaderElector,即一个DefaultLeaderElector类型的实例。
5. ONOS intra-clusters东西向通信
ONOS集群内的多个instance间通过TCP连接建立通信(目的端口是9876),包括Raft,Anti-entropy,Heatbeat以及其它的数据同步信息,ONOS通过数据包中的metadata来区分不同作用的数据信息。在任何两个ONOS实例间,可以同时建立多个TCP连接通信,这些TCP连接在需要时建立,若这些TCP连接空闲超过1min,TCP连接会中断。通过查看ControllerNode的代码实现,可以发现默认的9876端口信息:
ONOS基于Netty实现了一个异步的东西向通信消息服务接口(MessagingService),所有的东西通信都使用了这个消息服务接口,该消息接口是基于回调的思想实现的,MessagingService接口定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
/**
/**
* Interface for low level messaging primitives.
*/
public interface MessagingService {
/**
* Sends a message asynchronously to the specified communication end point.
* The message is specified using the type and payload.
* @param ep end point to send the message to.
* @param type type of message.
* @param payload message payload bytes.
* @return future that is completed when the message is sent
*/
CompletableFuture<Void> sendAsync(Endpoint ep, String type, byte[] payload);
/**
* Sends a message asynchronously and expects a response.
* @param ep end point to send the message to.
* @param type type of message.
* @param payload message payload.
* @return a response future
*/
CompletableFuture<byte[]> sendAndReceive(Endpoint ep, String type, byte[] payload);
/**
* Sends a message synchronously and expects a response.
* @param ep end point to send the message to.
* @param type type of message.
* @param payload message payload.
* @param executor executor over which any follow up actions after completion will be executed.
* @return a response future
*/
CompletableFuture<byte[]> sendAndReceive(Endpoint ep, String type, byte[] payload, Executor executor);
/**
* Registers a new message handler for message type.
* @param type message type.
* @param handler message handler
* @param executor executor to use for running message handler logic.
*/
void registerHandler(String type, BiConsumer<Endpoint, byte[]> handler, Executor executor);
/**
* Registers a new message handler for message type.
* @param type message type.
* @param handler message handler
* @param executor executor to use for running message handler logic.
*/
void registerHandler(String type, BiFunction<Endpoint, byte[], byte[]> handler, Executor executor);
/**
* Registers a new message handler for message type.
* @param type message type.
* @param handler message handler
*/
void registerHandler(String type, BiFunction<Endpoint, byte[], CompletableFuture<byte[]>> handler);
/**
* Unregister current handler, if one exists for message type.
* @param type message type
*/
void unregisterHandler(String type);
}
上面的消息服务接口中的每一个方法都有一个String type类型参数,表示的是该消息的类型。当消息到达Endpoint时,MessagingService会根据registerHandler注册的方法调用对应消息类型的处理方法,即message handler,从而完成消息的处理。
同时,为了方便使用东西向通信服务,ONOS又提供了一个集群通信服务服务接口(ClusterCommunicationService),通过使用该服务,可以很容易的实现东西数据的传输和处理。很多的最终一致性store都使用了ClusterCommunicationService,如ECDeviceStore,ECLinkStore,DistributedFlowRuleStore等,同时EventuallyConsistentMapImpl中的anti-entropy的实现也都使用了该服务。