Atomix是一个基于Raft协议的分布式协同框架,提供了集群管理,分布式存储等功能。其中,集群管理的一个基本功能就是集群的故障检测,也就是failure detector。下面将结合Atomix源码,分析基于Atomix的failure detector的实现机制。
在一个分布式系统中,可以通过心跳包(heartbeat)来实现故障检测。一个简单的实现方法如下:在本地保存一个心跳包的计时器,当收到一个节点的心跳包时就更新该计时器,表示该节点处于存活状态。当超过一定的时间(timeout)没有收到该节点的心跳包更新时,就认为该节点发生故障。
通过上述方法进行故障检测,可能引起如下问题:被检测的节点没有失效,但网络的时延增大或响应的时间较长导致检测节点超过timeout时间无法收到心跳包更新,这样会引起误判。因此基于上述方法进行故障检测时,timeout的值不能太小,例如Atomix的默认设置是5s,ZooKeeper是10s。然而,较大的timeout会导致系统故障发现的时间延长,影响系统的故障恢复。
1. φ failure detector
下面介绍一种提供连续的数值并根据数值的大小反映节点故障置信程度(suspicion level)的故障检测方法,同时,该方法也能够根据网络的状况动态调整故障的置信值的大小,从而在提高故障检测的正确性的同时减少故障检测的时间。另外由于该方法提供了一个连续的数值来反映故障检测的置信程度,系统中的不同应用可以根据自己对故障恢复的时间要求来动态调整故障的恢复时间。
1.1 φ failure detector的原理分析
如前文所述,系统中一个节点的失效检测的置信程度是一个随时间或网络状态变化的连续数值,即 φ,该值的计算方法如下:
$$\phi(t_{now}) = -log_{10}(P_{later}(t_{now} - T_{last}))$$
其中,$T_{last}$表示收到的心跳包的最新更新时间,$t_{now}$表示当前的时间,$P_{later}(t)$表示在上一个心跳包达到后,新的心跳包到达的时间间隔至少为 $t$ 的概率。
例如给定一个上限值$\Phi$,如果根据$\phi \ge \Phi = 1$来判定一个节点发生了故障,那么误判的概率为 $10\%$。类似的,当$\Phi = 2$时,误判概率为 $1\%$,当$\Phi = 3$时,误判概率为 $0.1\%$。
1.2 φ failure detector的实现
φ failure detector是要根据已知心跳包达到时间频率预测未来的心跳包间隔,因此 φ failure detector的实现主要包括两步:
- 统计过去一段时间窗口内的心跳包达到时间,窗口的大小固定,保存心跳包达到时间的个数为(WS),新的心跳包达到后将不断更新该窗口,并计算心跳包达到的平均时间间隔,方差等。
- 根据一个特定的概率分布式函数计算$P_{later}(t)$的大小。例如,假设心跳包达到的时间间隔服从正态分布,那么,$P_{later}(t)$的计算方法如下:
$$P_{later}(t) = \frac 1 {\sigma \sqrt{2\pi}} \int_{t}^{\infty}e^{- \frac {(x-\mu)^2} {2\sigma^2}} dx = 1 - F(t)
$$
2. Atomix中的故障检测的实现
如下图所示,基于Atomix实现分布式系统的故障检测,主要是通过分布式系统的各个节点与Atomix中保存的状态机建立会话连接(session),Atomix状态机通过检测各个会话连接是否存活来实现的。
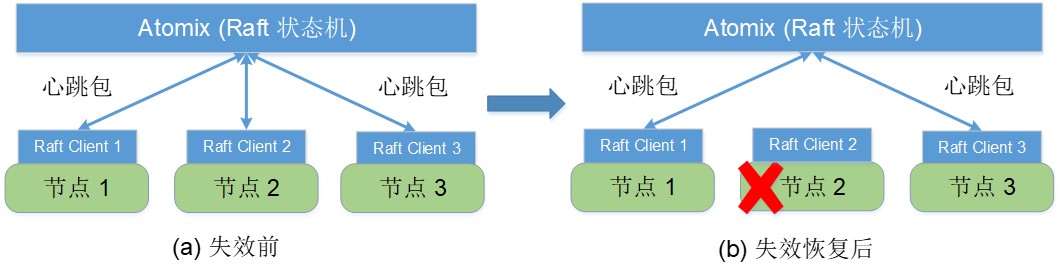
这里面的心跳包有两种,一种是由RaftClient发送的KeepAliveRequest请求,该请求最后由Raft状态机的Leader处理,Leader采用写日志并更新状态机的方式处理KeepAliveRequest请求,各个节点然后根据最近收到的KeepAliveRequest请求的时间与当前的时间间隔是否超出了timeout限制来判断一个RaftClient,也就是一个节点是否存活,详细的源码分析参考:Atomix源码分析:Raft Client的实现和与Server的交互。由于KeepAliveRequest请求需要经过Leader处理,并且更新状态机,过多的KeepAliveRequest请求会产生较大的系统开销。在系统默认参数的设置中,timeout为5s,各个session发送KeepAliveRequest的时间间隔是2.5~5s。因此,通过这种方式实现故障检测的时间较长,实验测得若timeout的设置为5s,故障检测的时间平均为5s左右。
另外一种心跳包就是实现φ failure detector的HeartbeatRequest,该心跳包由LeaderRole发送给各个RaftClient,然后通过φ failure detector来判断各个节点是否存活。由于HeartbeatRequest和HeartbeatResponse的发送和处理比简单,不会消耗过多的系统资源,因而可以较快的发送,Atomix中HeartbeatRequest的默认发送时间间隔是250ms。实验测得,使用了φ failure detector后,系统的故障检测时间可以缩短到1s左右。
由于φ failure detector可以缩短系统的故障检测时间,因此Atomix的FollowRole节点也使用φ failure detector来检测当前的LeaderRole是否存活,若判定当前的LeaderRole处于不存活状态,FollowerRole会转变成CandidateRole并完成领导选举。详细代码参考:FollowerRole
参考: